
Introducción: ¿Qué es un Protocolo de Anillo Redundante
En las redes Ethernet industriales, la fiabilidad operativa es absolutamente crítica para la misión. Una única falla en la red, como un cable dañado o un dispositivo averiado, puede interrumpir procesos productivos completos y ocasionar pérdidas económicas significativas. Para mitigar este riesgo, los switches industriales emplean tecnología de anillo redundante, que garantiza la continuidad operativa mediante el redireccionamiento automático del tráfico alrededor de la falla.
El principio fundamental del protocolo de anillo redundante consiste en bloquear lógicamente un enlace del anillo durante la operación normal, evitando así la formación de bucles en la red. Cuando se produce una falla, ya sea por desconexión de un enlace o fallos en un switch, el protocolo desbloquea automáticamente y de manera rápida (habitualmente en cuestión de milisegundos) el camino de respaldo para redirigir el tráfico, restaurando la comunicación sin intervención humana.
Este mecanismo asegura que ni siquiera un único punto de falla interrumpa los servicios de red, incrementando notablemente la disponibilidad del sistema. Resulta especialmente adecuado para entornos industriales que exigen alta fiabilidad y desempeño en tiempo real.
En este artículo, analizaremos los protocolos de anillo redundante más comunes empleados para garantizar la redundancia en redes Ethernet industriales.
Artículo relacionado: What Is Network Redundancy? How to Implement Redundancy in Industrial Switches?
Protocolos Comunes de Anillo Redundante
En las infraestructuras Ethernet industriales existen diversos protocolos de redundancia en anillo. El presente artículo se enfoca en los más comunes y estandarizados:
- STP/RSTP/MSTP
- ERPS
- EAPS
- MRP
Cada protocolo ofrece mecanismos diferenciados, tiempos de recuperación variados y distintos niveles de interoperabilidad. En este artículo no se abordan protocolos propietarios, como el Turbo Ring de Moxa o el HRP de Hirschmann.
STP / RSTP / MSTP
La familia de protocolos Spanning Tree Protocol (STP) es un conjunto de estándares IEEE ampliamente utilizados en redes Ethernet generales y algunas aplicaciones industriales.
Funcionamiento de STP
- Intercambio de BPDU: Tras el arranque, los switches envían periódicamente Unidades de Datos de Protocolo de Puente (BPDU) para descubrir la topología de la red.
- Elección del Root Bridge: Todos los switches comparan sus IDs de puente (prioridad + dirección MAC); el que posee el valor más bajo se convierte en Root Bridge.
- Cálculo de rutas: Cada switch no raíz determina el camino más corto hacia el Root Bridge según el costo del trayecto.
- Asignación de roles a los puertos: Los switches designan un Root Port (mejor camino al Root Bridge) y Puertos Designados (encargados de transmitir tráfico en cada segmento).
- Bloqueo de puertos redundantes: Se colocan en estado de bloqueo todos los puertos que podrían generar bucles, impidiendo la transmisión de datos pero manteniendo la supervisión de BPDUs.
- Ante la falla de un enlace o dispositivo: Los switches detectan el cambio mediante BPDUs, recalculan el árbol de expansión y desbloquean puertos según sea necesario.
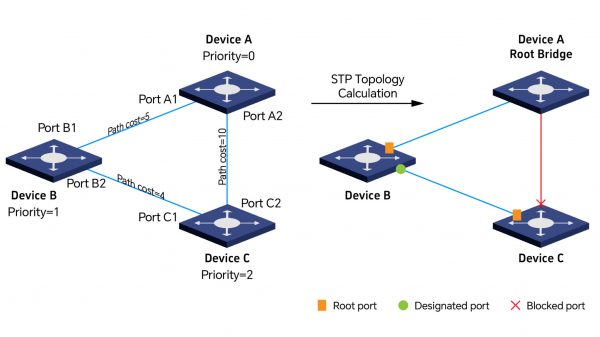
La explicación anterior describe el principio básico de STP. Sin embargo, su versión original presenta tiempos de recuperación relativamente prolongados, lo que limita su aplicación en entornos que requieren respuestas en tiempo crítico. Para subsanar esta limitación, se desarrollaron dos versiones mejoradas: RSTP (Rapid Spanning Tree Protocol) y MSTP (Multiple Spanning Tree Protocol), que ofrecen una convergencia más rápida y mayor versatilidad en redes industriales modernas.
- STP: Versión básica que evita bucles bloqueando enlaces redundantes y creando una topología lógica libre de bucles. Su convergencia es lenta, requiriendo típicamente 30–50 segundos para recuperar la red.
- RSTP: Versión mejorada que logra una convergencia más rápida, generalmente entre 1 y 10 segundos.
- MSTP: Basado en RSTP, permite mapear múltiples VLANs a una única instancia de árbol de expansión, facilitando el balanceo de carga entre VLANs. Mantiene compatibilidad con versiones anteriores (STP y RSTP) y su tiempo de convergencia también es inferior a 10 segundos.
Al ser un estándar internacional, la familia Spanning Tree Protocol ofrece excelente interoperabilidad y soporte para diversas topologías físicas. No obstante, en redes industriales de gran envergadura o complejidad, su desempeño en convergencia puede resultar insuficiente frente a protocolos de anillo industrial dedicados, siendo más adecuado para aplicaciones no críticas en tiempo o como mecanismo de respaldo.
MRP
El Protocolo de Redundancia de Medios (Media Redundancy Protocol, MRP), definido en la norma IEC 62439-2, es un protocolo industrial estandarizado para redundancia en anillos Ethernet diseñado para recuperaciones de red de alta velocidad.
En un anillo MRP, un dispositivo se designa como Gestor de Redundancia de Medios (MRM), mientras que los demás funcionan como Clientes de Redundancia de Medios (MRC). El MRM supervisa continuamente el estado del anillo y bloquea habitualmente uno de sus puertos para evitar bucles en la red. Ante una falla en un enlace o dispositivo, el MRM desbloquea de inmediato dicho puerto, permitiendo que el tráfico se desvíe por la ruta alternativa.
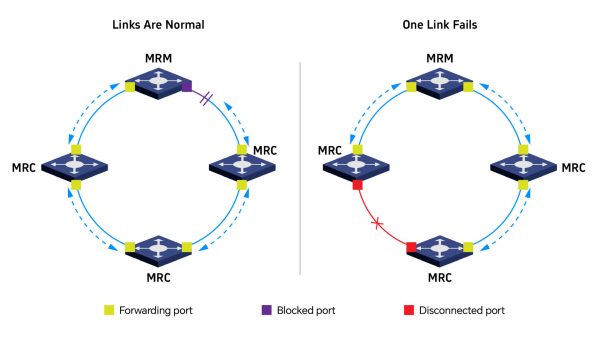
MRP ofrece configuraciones de recuperación flexibles, con tiempos típicos de recuperación de 500 ms, 200 ms, 60 ms, 15 ms, e incluso menos de 10 ms en anillos pequeños (hasta 50 switches).
Como estándar industrial internacional, MRP está respaldado por numerosos fabricantes de equipos de automatización. Proporciona una recuperación significativamente más rápida que STP, lo que lo hace ideal para automatización industrial y sistemas de control en tiempo real.
ERPS
Ethernet Ring Protection Switching (ERPS) es un protocolo de redundancia de grado operador diseñado específicamente para redes en anillo Ethernet, estandarizado bajo ITU-T G.8032.
El principio de funcionamiento de ERPS consiste en designar un switch como propietario del Enlace de Protección del Anillo (RPL). En condiciones normales, el propietario del RPL bloquea un enlace del anillo para evitar bucles de red. El protocolo intercambia continuamente mensajes de control (tramas R-APS) entre todos los nodos del anillo para monitorear el estado de los enlaces. Ante una falla, los nodos afectados notifican inmediatamente al propietario del RPL, quien desbloquea el enlace previamente bloqueado, permitiendo la redirección del tráfico por el camino de respaldo.
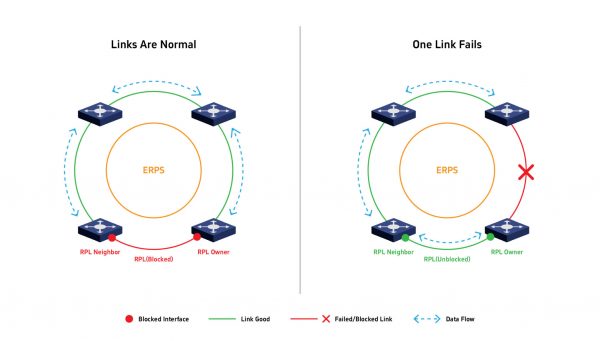
La principal ventaja de ERPS radica en su recuperación ultraveloz, típicamente inferior a 50 ms, lo cual lo hace idóneo para la automatización industrial, manufactura inteligente y otras aplicaciones críticas que exigen alta fiabilidad y tiempo mínimo de inactividad.
EAPS
EAPS (Ethernet Automatic Protection Switching) es un protocolo de protección rápida desarrollado originalmente por Extreme Networks para topologías de anillo Ethernet. Gracias a su eficiencia y diseño robusto, su mecanismo central fue estandarizado como IETF RFC 3619, convirtiéndolo en una tecnología pública y abierta. Sin embargo, en redes reales, distintos fabricantes pueden implementar y extender RFC 3619 con ligeras variaciones.
¿Cómo funciona EAPS?
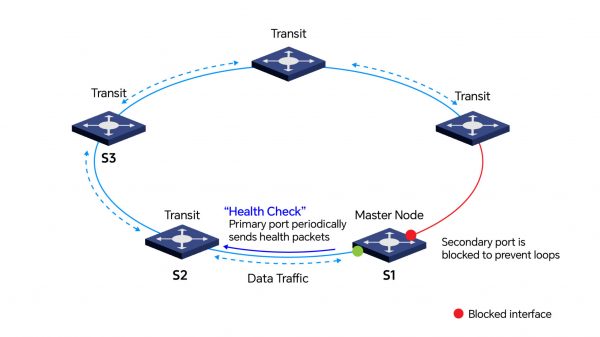
- El nodo maestro envía periódicamente paquetes de integridad para supervisar la integridad del anillo. El puerto secundario permanece bloqueado normalmente para evitar bucles.
- Ante una falla de enlace, el maestro habilita el puerto secundario para reenvío y emite un mensaje Flush-FDB para redirigir el tráfico por la ruta alternativa.
- Al restaurarse el enlace, el maestro vuelve a bloquear el puerto secundario y envía un mensaje Complete-Flush-FDB para restablecer el reenvío normal.
- La recuperación suele completarse en menos de 50 ms, garantizando alta disponibilidad de la red.
EAPS opera de manera similar a ERPS, pero se diferencia en aspectos clave. EAPS depende de un nodo maestro único que gestiona tanto el bloqueo como la recuperación, mientras que ERPS utiliza un modelo de propietario y vecino RPL para gestionar los enlaces bloqueados. Además, ERPS soporta topologías de anillos más complejas y múltiples dominios de anillo, mientras que EAPS está diseñado principalmente para anillos simples o dobles.
Comparativa de Rendimiento entre Protocolos de Redundancia en Anillo
Para una visión resumida, la siguiente tabla sintetiza las características principales.
| Protocolo | Tiempo Típico de Recuperación | Escala de Dispositivos / Red | Fortalezas Principales | Debilidades / Notas |
| STP | 30 – 50 segundos | Sin límite específico | Protocolo original que previene bucles básicos. | Demasiado lento para redes actuales. Protocolo obsoleto, no recomendado para nuevas implementaciones. |
| RSTP | 1 – 10 segundos | Sin límite específico | Convergencia mucho más rápida que STP. Compatibilidad universal. Soporta cualquier topología física. | La convergencia puede ser lenta en redes grandes o complejas. No es óptimo para anillos críticos en tiempo. |
| MSTP | ≤ 10 segundos | Sin límite específico | Permite balanceo de carga entre VLANs. Compatible con RSTP/STP. | Configuración más compleja. La velocidad de convergencia sigue siendo del orden de segundos. |
| MRP | < 10 – 500 ms (configurable) | Hasta 50 switches | Estándar internacional industrial. Optimizado para PROFINET. Comportamiento determinista. | Limitado a topologías en anillo. |
| ERPS | < 50 ms | Hasta 255 nodos por anillo | Estándar internacional de calidad telecom. Excelente para entornos multi-fabricante. | Restringido a topologías en anillo. La opción preferente para anillos estándar de alta velocidad. |
| EAPS | < 50 ms | Normalmente anillo simple o doble | Convergencia rápida, mecanismo sencillo, rentable. | Menos común que ERPS/MRP, mayormente reemplazado. |
Cómo Elegir el Protocolo Adecuado para Su Red
Para determinar el protocolo de anillo redundante óptimo, evalúe sus necesidades considerando estas tres dimensiones críticas:
Topología y Escala de la Red
Restricción: ¿Anillo físico limpio?
- Sí: Opte por protocolos optimizados para anillos (MRP, ERPS, propietarios).
- No: RSTP/MSTP es la opción principal para gestionar topologías en malla arbitrarias, aceptando una convergencia más lenta (1-10 segundos).
Rendimiento: Objetivo de Tiempo de Recuperación (RTO)
- Tolerancia > 1 segundo: RSTP/MSTP resulta adecuado para operaciones no críticas.
- Requisito < 100 ms: Implica la necesidad de un protocolo de anillo dedicado (MRP, ERPS, propietario).
¿Cuáles Son Sus Objetivos Técnicos y de Mantenimiento?
Ejemplo A: Sistemas Industriales Específicos
Si su red presta servicio principalmente a sistemas industriales de campo como PROFINET, que demandan requisitos de protocolo estrictos, MRP suele ser el estándar de facto o mandatorio. Adoptar MRP garantiza la mejor compatibilidad y un rendimiento determinista con los dispositivos.
Ejemplo B: Alto Rendimiento, Compatibilidad Multi-vendedor y Flexibilidad Futura
Para redes que funcionan como columna vertebral en fábricas o centros de datos integrando dispositivos de múltiples proveedores y que buscan evitar el encasillamiento con un solo fabricante, ERPS es la opción ideal. Este estándar internacional de nivel carrier ofrece una recuperación inferior a 50 ms, una excelente interoperabilidad multi-vendedor y una escalabilidad a largo plazo para futuras actualizaciones.
Switch Industrial Ethernet Redundante
Como se mencionó anteriormente, los mecanismos de redundancia en anillo están generalmente integrados en switches Ethernet. Estos dispositivos constituyen el pilar de las redes industriales extensas, desempeñando un papel fundamental en la estabilidad y alta disponibilidad de la red.
Los switches industriales gestionados de Come-Star son una opción excepcional para construir redes Ethernet en anillo confiables. Admiten todos los principales protocolos de redundancia en anillo, incluyendo:
- STP / RSTP / MSTP
- MRP
- ERPS
- EAPS
Además de soportar diversos protocolos de redundancia, los switches Come-Star cuentan con diseños de alta confiabilidad, tales como:
- Hardware robusto — Amplio rango de temperatura operativa, resistencia al polvo y agua, así como a vibraciones, impactos y radiaciones electromagnéticas.
- Entradas de alimentación redundantes — Garantizan operación continua ante fallos en la alimentación eléctrica.
- Configuraciones flexibles de puertos — Opciones que incluyen puertos de cobre y fibra óptica, velocidades desde 100 Mbps hasta 10 Gbps, y capacidad PoE, para satisfacer diversas exigencias de redes industriales.
Con estas características, los switches industriales de Come-Star proporcionan alto desempeño, robustez y resistencia de red, asegurando una comunicación ininterrumpida incluso en entornos exigentes.
Artículo relacionado: Diseño de Redes en Anillo de Fibra Óptica Explicado: Topologías, Diagramas y Consideraciones para Switches
Reflexiones Finales
Tras la lectura de este artículo, dispondrá de un entendimiento más claro sobre los protocolos de anillo redundantes más utilizados en redes Ethernet industriales. Si desea profundizar en sus principios de funcionamiento y aplicaciones prácticas, le invitamos a visitar nuestro blog, donde compartimos regularmente conocimientos sobre tecnologías de redes industriales.
En entornos industriales contemporáneos, construir una red Ethernet redundante es fundamental para garantizar la fiabilidad operativa y minimizar tiempos de inactividad. Si planea establecer una infraestructura industrial de comunicación redundante, los switches gestionados de Come-Star están diseñados para satisfacer sus requerimientos. Nuestros switches redundantes de red, diseñados específicamente para sistemas de control industrial, soportan el protocolo propietario de Come-Star con tiempos de recuperación inferiores a 20 ms. Son compatibles con los protocolos de redundancia más relevantes y presentan un diseño robusto y duradero, que proporciona una base sólida y confiable para su infraestructura de comunicación industrial.